排序
排序的相关概念
- 数据表:待排序的数据元素的集合。通常组织为顺序表、静态链表、动态链表等形式,也可以用完全二叉树的顺序组织。
- 排序码:数据元素中的某个数据项,作为排序依据的属性。
- 排序的确切定义:设含有含有
个元素的序列为 , 的排序码为 ,排序的目的是使得确定 的一个排列 ,使得 - 原地排序:只用了规模为
的辅助空间,排序结果仍然在原来的存储空间中。 - 稳定性:排序后相同关键字的元素的相对位置不变。
- 排序方法分类
- 有序区增长:将数据表分为有序区和无序区,在排序过程中逐步扩大有序区,缩小有序区,直到整个数据表有序。
- 有序程度增长:不能明确区分有序区和无序区,而是逐步增加有序程度。
- 内排序与外排序
- 内排序:整个排序过程在内存中完成。
- 外排序:数据量太大,无法一次性装入内存,需要借助外存进行排序。
- 静态排序与动态排序
- 静态排序:数据表在排序过程中不涉及插入、删除等操作,仅交换元素位置。
- 动态排序:数据表在排序过程中可能会有插入、删除等操作。常见于动态链表和树形结构。
数据表
与本书中定义的顺序表不同,下标从
插入排序
直接插入排序
假设
void InsertSort(&L)
{
for (i = 1; i <= L.n - 1; ++i)
{
tmp = L.data[i];
for (j = i - 1; j >= 0 && L.data[j] > tmp; --j)
L.data[j + 1] = L.data[j];
L.data[j + 1] = tmp;
}
}直接插入排序的时间复杂度为
折半插入排序
在直接插入排序的基础上,使用二分查找找到插入位置。
void BinaryInsertSort(&L)
{
for (i = 1; i <= L.n - 1; ++i)
{
tmp = L.data[i];
low = 0, high = i - 1;
while (low <= high)
{
mid = (low + high) / 2;
if (L.data[mid] > tmp)
high = mid - 1;
else
low = mid + 1;
}
// low == high + 1
for (j = i - 1; j >= high + 1; --j)
L.data[j + 1] = L.data[j];
L.data[high + 1] = tmp;
}
}比较次数为
希尔排序
void InsertSortGap(L, start, gap)
{
for (i = start + gap; i < L.n; i += gap)
if (L.data[i] < L.data[i - gap])
{
tmp = L.data[i];
for (j = i - gap; j >= 0 && L.data[j] > tmp; j -= gap)
L.data[j + gap] = L.data[j];
L.data[j + gap] = tmp;
}
}
void ShellSort(L, d[], m)
{
for (i = 0; i < m; ++i)
for (start = 0; start < d[i]; ++start)
insertSort_gap(L, start, d[i]);
}希尔排序的时间复杂度基于增量序列的选择。 让
交换排序
起泡排序
void BubbleSort(&L)
{
for (i = 0; i < L.n - 1; ++i)
{
flag = false;
for (j = L.n - 1; j > i; --j)
if (L.data[j] < L.data[j - 1])
{
swap(L.data[j], L.data[j - 1]);
flag = true;
}
if (!flag)
return;
}
}起泡排序的时间复杂度为
快速排序
int Partition(&L, left, right)
{
k = left;
pivot = L.data[left];
for (i = left + 1; i <= right; ++i)
if (L.data[i] < pivot)
{
++k;
swap(L.data[k], L.data[i]);
}
L.data[left] = L.data[k];
L.data[k] = pivot;
return k;
}
void QuickSort(&L, left, right)
{
if (left < right)
{
k = Partition(L, left, right);
QuickSort(L, left, k - 1);
QuickSort(L, k + 1, right);
}
}快速排序的平均时间复杂度为
优化
快速-插入排序
void QuickInsertSort(&L, left, right)
{
if (right - left <= M)
InsertSort(L, left, right);
else
{
k = Partition(L, left, right);
QuickInsertSort(L, left, k - 1);
QuickInsertSort(L, k + 1, right);
}
}选基准记录的三者取中快速算法
DataType Median3(&L, left, right)
{
mid = (left + right) / 2;
if (L.data[left] > L.data[mid])
swap(L.data[left], L.data[mid]);
if (L.data[left] > L.data[right])
swap(L.data[left], L.data[right]);
if (L.data[mid] > L.data[right])
swap(L.data[mid], L.data[right]);
swap(L.data[mid], L.data[left]);
return L.data[left];
}
int Partition(&L, left, right)
{
pivot = Median3(L, left, right);
i = left, j = right;
while (i < j)
{
while (i < j && L.data[j] >= pivot)
--j;
while (i < j && L.data[i] <= pivot)
++i;
if (i < j)
swap(L.data[i], L.data[j]);
}
}选择排序
简单选择排序
void SelectSort(&L)
{
for (i = 0; i < L.n - 1; ++i)
{
k = i;
for (j = i + 1; j < L.n; ++j)
if (L.data[j] < L.data[k])
k = j;
if (k != i)
swap(L.data[i], L.data[k]);
}
}锦标赛排序
进行
堆排序
void HeapSort(&H)
{
for (i = H.n / 2 - 1; i >= 0; --i)
siftDown(H, i, H.n - 1);
for (i = H.n - 1; i > 0; --i)
{
swap(H.data[0], H.data[i]);
siftDown(H, 0, i - 1);
}
}堆排序的时间复杂度为
归并排序
二路归并排序
void Merge(&L, left, mid, right)
{
i = left, j = mid + 1, k = 0;
tmp = new DataType[right - left + 1];
while (i <= mid && j <= right)
if (L.data[i] <= L.data[j])
tmp[k++] = L.data[i++];
else
tmp[k++] = L.data[j++];
while (i <= mid)
tmp[k++] = L.data[i++];
while (j <= right)
tmp[k++] = L.data[j++];
for (i = 0; i < k; ++i)
L.data[left + i] = tmp[i];
delete[] tmp;
}
void MergeSortRecur(&L, left, right)
{
if (left < right)
{
mid = (left + right) / 2;
MergeSortRecur(L, left, mid);
MergeSortRecur(L, mid + 1, right);
Merge(L, left, mid, right);
}
}归并排序的时间复杂度为
基数排序
MSD 基数排序
Most Significant Digit,从高位到低位进行排序。 所以是递归的,每次递归对某一位进行排序。
void MSDRadixSort(int A[], int left, int right, int k)
{
if (left >= right || k > d)
return;
int *count = new int[radix]();
int *posit = new int[radix]();
int *auxArray = new int[right - left + 1];
for (int i = left; i <= right; ++i)
++count[getDigit(A[i], k)];
posit[0] = 0;
for (int i = 1; i < radix; ++i)
posit[i] = posit[i - 1] + count[i - 1];
for (int i = left; i <= right; ++i)
auxArray[posit[getDigit(A[i], k)]++] = A[i];
for (int i = left; i <= right; ++i)
A[i] = auxArray[i - left];
delete[] auxArray;
int p1 = left;
for (int i = 0; i < radix; ++i)
{
int p2 = p1 + count[i] - 1;
MSDRadixSort(A, p1, p2, k + 1);
p1 = p2 + 1;
}
delete[] count;
delete[] posit;
}LSD 基数排序
Least Significant Digit,从低位到高位进行排序。 共进行
void LSDRadixSort(StaticLinkList &SL)
{
int rear[radix], front[radix];
for (int i = d; i >= 1; --i)
{
for (int j = 0; j < radix; ++j)
front[j] = 0;
for (int s = SL.elem[0].link; s != 0; s = SL.elem[s].link)
{
int k = getDigit(SL.elem[s].key, i);
if (front[k] == 0)
front[k] = s;
else
SL.elem[rear[k]].link = s;
rear[k] = s;
}
int j = 0;
while (front[j] == 0)
++j;
SL.elem[0].link = front[j];
int last = rear[j];
for (int k = j + 1; k < radix; ++k)
if (front[k] != 0)
{
SL.elem[last].link = front[k];
last = rear[k];
}
SL.elem[last].link = 0;
}
}基数排序的时间复杂度为
排序的下界
比较排序的下界
判定树模型:将排序算法的比较过程抽象为一棵二叉树,树的每个非叶结点表示一次比较,每个叶结点表示一种排序结果。 共有
排序方法性能比较
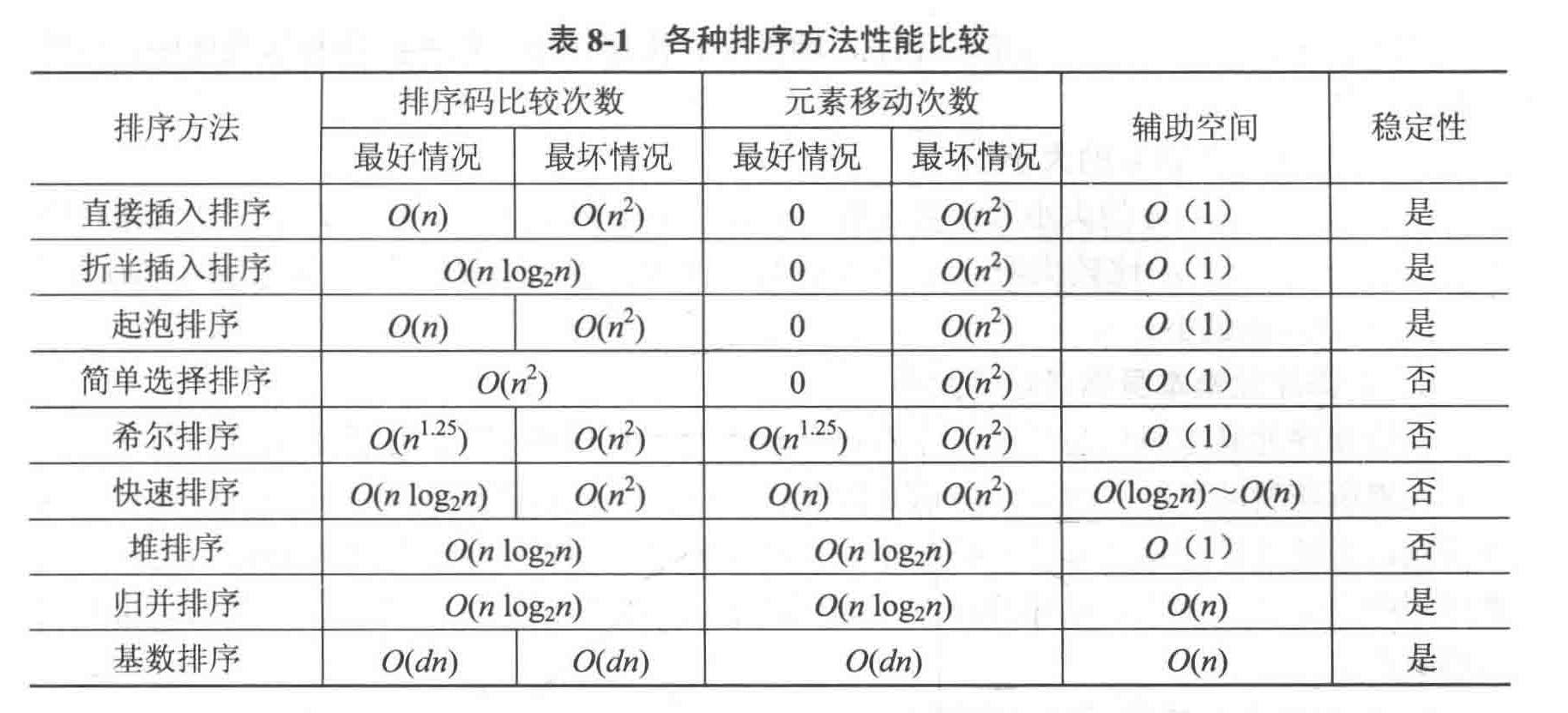
数据规模较小或者较为有序时,插入排序和冒泡排序的性能较好。
- 简单排序算法:直接插入排序、折半插入排序、起泡排序、简单选择排序。
- 改进排序算法:希尔排序、堆排序、快速排序、归并排序、基数排序。
外排序
由于访问外存的速度远远低于内存,需要考虑如何使外存的访问次数尽可能少。
存储设备和缓冲区
- 磁带:顺序访问,不适合随机访问。
- 磁盘:尽量把相关信息放在同一柱面或者相邻柱面,减少寻道时间。
- 缓冲区:内存中的一块区域,用于存放外存中的数据。可以看作是一个队列,先进先出。
基于磁盘的外排序
- 建立用于外排序的内存缓冲区。将他们的大小分为若干段,使用某种内排序方法对每一段进行排序。这些经过排序的段叫做归并段或初始顺串(Run)。生成后就被写在外存中去。
- 仿照内排序种所介绍过的归并树,对这些归并段进行归并,直到得到一个有序的文件。
分别为内排序时间、外存读写时间、归并时间。
需要减小外部读写的时间。